

Other recent blogs



In 2026, the Indian enterprise landscape has officially moved past the "AI hype" phase. Major conglomerates, fintech unicorns, and manufacturing giants in India are no longer asking if they should use AI, but rather how to scale it. The bottleneck is no longer the algorithms; it’s the plumbing. According to NASSCOM, while 80% of Indian organizations are exploring Agentic AI, nearly half remain stuck in the middle stage of maturity due to fragmented data silos. This brings us to the ultimate architectural showdown: Data Fabric vs. Data Lake. This comprehensive guide explores which of the two architectures Indian enterprises need to build truly AI-ready cloud data platforms in 2026.
The 2026 Reality: Why Traditional Data Lakes Are Not Enough
For the past decade, the Data Lake was the go-to solution. It was a cost-effective dumping ground for raw data, both structured and unstructured. However, as we enter 2026, the limitations of a standalone data lake have become evident:
- Data Swamp Risk: Without a robust, automated governance layer, Indian enterprises often find their data lakes deteriorating into data swamps filled with dark data. This refers to a vast amount of unlabelled, untrusted, and redundant information that remains hidden from analytics tools. In 2026, such unmanaged data is not only a storage liability but a direct threat to AI accuracy, as models trained on "swampy" data often produce biased or hallucinated results
- Latency in Localized Context: With India's Digital Personal Data Protection (DPDP) Act now fully operational, strict data residency and sovereignty rules make moving data across borders or even internal regions legally complex. A traditional centralized data lake often creates significant latency issues because it requires physical data movement (ETL,) which struggles to keep up with real-time AI needs.
- The AI Readiness Gap: While Gartner reports that 57% of organizations feel their data isn't AI-ready, the issue in 2026 is no longer about quantity; it’s about context. A data lake provides the necessary volume of raw data for training, but it lacks the semantic layer( meanings and relationships) that large language models and Agentic AI require to function effectively. To bridge this gap, enterprises need an architecture that doesn't just store bits and bytes, but intelligently maps how different data points relate to business processes.
Defining the Contenders in 2026
What is a Data Lake (and Lakehouse) in 2026?
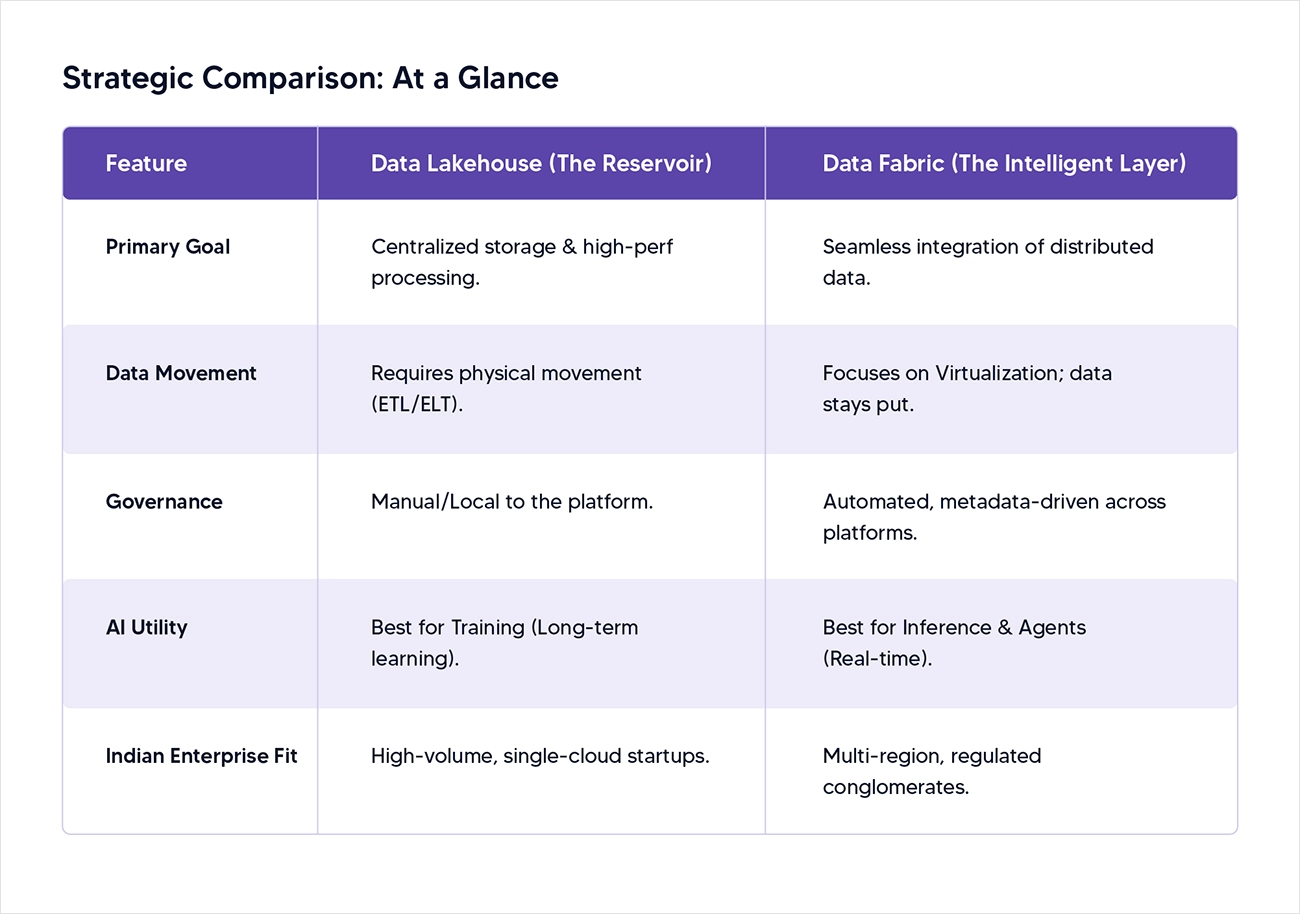
The modern Data Lake has evolved into a Data Lakehouse - a centralized repository using open formats like Apache Iceberg or Delta Lake. Kellton’s Data Lake solutions help enterprises build this foundation by combining the low-cost storage of a lake with the ACID transactions of a warehouse.”It combines the low-cost storage of a lake with the ACID transactions of a warehouse. It successfully bridges the gap between raw data storage and structured querying. In 2026, architecture is no longer a storage choice but a strategic necessity, as it provides the transactional reliability of a traditional warehouse with the petabyte-scale flexibility of a cloud-based lake.
- Ideal for: Deep historical analysis and training massive ML models. The Data Lakehouse is the perfect environment for training foundational Large Language Models (LLMs) from scratch or performing complex time-travel queries to analyze historical trends over many years.
- Indian Context: Best for sectors like healthcare (storing decades of patient records) or E-commerce (storing massive clickstream logs). In the Indian market, this is a game-changer for Healthcare giants managing massive repositories of diagnostic images and patient histories, as well as E-commerce platforms that need to ingest billions of clickstream events every day.
Deep Dive: Modern Data Lake Architecture (2026)
In 2026, a robust Data Lakehouse architecture is no longer a "flat" storage space; it is a multi-layered ecosystem designed for performance and reliability.
- Ingestion & Staging Layer: This data lake architecture supports high-velocity streaming (e.g., Kafka) and batch loads, landing data in a "Raw Zone."
- Open Table Formats: Modern data lake architecture relies on Apache Iceberg or Delta Lake, ensuring that multiple AI engines can read the same data simultaneously with full ACID integrity.
- The Medallion Framework: A standard data lake architecture now follows the Bronze-Silver-Gold approach, progressively refining data until it is "Gold" grade and ready for AI consumption.
- Catalog & Governance Layer: Centralized services like Databricks Unity Catalog or AWS Glue provide the single source of truth for schema management.
What is a Data Fabric in 2026?
A Data Fabric is not a storage bucket; it is an important metadata-driven layer that sits on top of all your data sources (lakes, warehouses, edge devices). Unlike traditional architectures that require you to move data into a single bucket, a Data Fabric creates a virtualized, metadata-driven layer that weaves together data from on-premises servers, multiple clouds, and edge devices. By leveraging active metadata and AI-powered knowledge graphs, the fabric automatically discovers, cleans, and connects disparate datasets in real time.
- Ideal for: Real-time access, multi-cloud environments, and federated governance. Data Fabric is the ultimate solution for organizations that need to provide immediate, trusted data access to various business units simultaneously. Because it uses automated policy enforcement, security and compliance rules are applied instantly at the moment of access, regardless of where the data lives.
- Indian Context: Complex, multi-region sectors like BFSI and Retail. For Indian Banks and Fintechs, a Data Fabric is critical for bridging the gap between decades-old mainframe systems and modern, mobile-first banking apps. It allows a bank in Mumbai to perform real-time fraud detection by analyzing transaction data sitting in an on-premise database alongside customer behavior data stored in the cloud.
Deep Dive: Data Fabric Architecture (2026)
A data fabric architecture is fundamentally different from a lake as it focuses on connectivity over collection.
- Active Metadata Layer: In a data fabric architecture, AI observes data usage patterns to automatically suggest security tags and governance policies.
- Knowledge Graph Engine: This component of data fabric architecture maps relationships between data entities (e.g., "Customer A" in the CRM is the same as "Account 123" in the Banking Core), providing the context AI agents need.
- Data Virtualization Plane: A key pillar of data fabric architecture, this allows users to run a single SQL query that pulls data from an on-prem Oracle DB in Mumbai and an S3 bucket in a cloud region simultaneously, without the data ever being copied.
- Orchestration & Delivery: This layer of the data fabric architecture automates the delivery of curated data "products" to end-users or AI agents via APIs.
Strategic Comparison: At a Glance
Why Indian Enterprises Need Data Fabric for AI Readiness

While a Data Lake is a necessary foundation, the Data Fabric is the "AI-ready" accelerator for modern cloud data platforms. In 2026, the success of your AI strategy depends less on the models you choose and more on how seamlessly your data can be discovered, governed, and delivered to those models in real-time. By implementing a fabric architecture, Indian enterprises can transition from reactive data management to a proactive AI-first stance that treats data as a dynamic living asset rather than a dormant resource. Here is why Indian CXOs are pivoting toward Fabric in the Data Fabric vs. Data Lake debate:
1. Solving the sovereignty vs speed dilemma: With the RBI and the government of India pushing for local data residency, enterprises cannot always move data to global cloud regions. A data fabric allows an Indian bank to keep sensitive KYC data on a local server in Mumbai while allowing an AI model in a public cloud to query it via virtualization, complying with the DPDP act without moving the physical file. This "compliance-by-design" approach enables organizations to innovate at cloud speed while remaining 100% compliant with local laws, effectively turning a regulatory hurdle into a competitive advantage.
2. Empowering Agentic AI: 2026 is the year of AI Agents. Unlike a standard chatbot, an agent needs to "browse" your enterprise data to complete a task.To understand how these agents function beyond simple prompts, explore the various Agentic AI applications currently transforming the enterprise landscape. A Data Fabric provides the Knowledge Graph that allows these agents to understand the relationship between vendors, invoices, and payments across different silos instantly. By linking disparate data points across silos—such as connecting a customer’s recent support ticket in Zendesk to their purchase history in an on-prem ERP- the fabric ensures that Retrieval Augmented Generation(RAG) systems provide hallucination-free responses that are grounded in the absolute latest enterprise reality.
3. Overcoming the Talent Gap: India has a massive pool of software engineers, but a shortage of Data Janitors (those who spend 80% of their time cleaning data). Data fabric leverages augmented data management to automate metadata tagging and cleanup, enabling the Indian workforce to focus on high-value AI innovation. This allows your existing workforce to shift their focus from tedious ETL (Extract, Transform, Load) tasks to high-value Context Engineering, ensuring that your human talent and your AI agents are working on the innovations that will actually drive revenue growth in the Indian market.
Real-World Use Cases in 2026 India: Data Fabric & Data Lake in Action
The Data Fabric vs Data Lake debate isn't just academic; it is being settled on the ground in India’s most competitive sectors. As of 2026, the most successful enterprises are no longer treating these as competing products, but as complementary layers that solve specific business pain points. From the smart factories to the high-speed fintech hubs in India, here is how the "AI-Ready" cloud platform is being deployed in the real world to drive measurable ROI.
1. Manufacturing: The Predictive Power of the Lakehouse. Indian manufacturing giants are using Data Lake architecture to store petabytes of high-frequency sensor data from IoT-enabled shop floors to predict machine failures before they happen. By training deep learning models on years of vibration, heat, and pressure logs, these firms have reduced unplanned downtime by up to 30% saving crores in lost production time. This centralized approach ensures that massive historical datasets are always available for the heavy-duty ML training required to optimize long-term asset lifecycles.
2. Retail & ONDC: Real-Time Agility via Data Fabric With the ONDC (Open Network for Digital Commerce) ecosystem now dominating Indian retail, brands are using Data Fabric to unify inventory data across thousands of small kirana stores with real-time sales logs with digital apps. This allows a retailer to offer hyper-local dark store deliveries within 10 minutes by virtualizing data from disparate point-of-sale(POS) systems without moving them to a central server. By connecting the dots between local stock and national demand in real-time, the fabric layer empowers retail AI to adjust pricing and logistics dynamically every second.
3. Fintech (Bengaluru): The "Security Fabric" for Fraud Prevention. In 2026, when India processes over 700 million UPI transactions daily, leading fintechs use a hybrid model where a Data Lake stores credit history while a data fabric provides a real-time security layer. The fabric analyzed behavioral biometric and transaction velocity across multiple payment methods gateways , instantly blocking fraudulent credential stuffing attacks before the funds even leave the account.
Conclusion: The Verdict for 2026
In 2026, the Data Lake is your storage foundation, but the Data Fabric is your competitive advantage. For Indian enterprises dealing with hybrid infrastructure, strict regulations, and aggressive push towards AI agents, a data fabric approach is the smartest investment for their cloud data platforms. It provides the agility to innovate without the technical debt of massive, rigid data migrations. Ultimately, the future of the Indian enterprise belongs to those who can connect their data faster than they can collect it. As an AI-first digital transformation partner, Kellton helps enterprises bridge the gap between experimental AI and production-ready AI by architecting unified data foundations that combine the cost-efficiency of Data Lakehouses with the intelligent, real-time orchestration of a Data Fabric.
Frequently Asked Questions(FAQ)
Q1. In the context of Data Fabric vs. Data Lake, is Fabric a replacement for the Lake?
Answer: No. Think of the Data Lake as the library (where books are stored) and the Data Fabric as the digital librarian who knows exactly where every piece of information is, and even if it is in a different city, it can bring it to you instantly.
Q2. Which one is more expensive for an Indian firm?
Answer: A Data Lake has lower upfront storage costs, but high long-term hidden costs in engineering. A data fabric has higher initial license costs but significantly reduces operational overhead.
Q3. How does the DPDP Act affect this?
Answer: The DPDP Act makes governance non-negotiable. Data Fabric is superior for compliance because it allows for "Attribute-Based Access Control" (ABAC) across all systems from a single pane of glass without duplicating sensitive data.
Q4. Which is better for RAG (Retrieval-Augmented Generation)?
Answer: Data Fabric. RAG requires the most recent, governed data. While a data lake might have old versions of a document, a fabric can pull the live authorized version directly from the source system for the AI to use.


